Event Sourcing
Event sourcing is an architectural design pattern that uses an append-only store to record the actions taken on the data.
Let me start with the context and the problem. Most of the applications apply the typical approach which maintains the state of the data by using CRUD operations. i.e, reads data from store, update its values and put new values into store. Here are the limitations:
- These read-update-write operations can slow down performance ans responsiveness due to process overhead.
- Data updates may cause conflicts, need extra logic to handle concurrency and locking.
- Only the current state is recorded, operation history is lost.
The solution suggested is event sourcing pattern. Instead of storing the current state, this pattern offers to record events in a sequence in an append-only store where event represents a set of changes to the data (such as AddedItemIntoInventory).
Best example of event sourcing is version control systems as svn, git. Version control systems stores current state as diffs. The current state is your latest source code, and events are your commits representing the change.
Unlike the typical approach, update and delete operations are forbidden in event sourcing. Since the events are recorded (not states), these should not be updated or deleted — event store is like history and we cannot change history. All the events should remain as created in the event store.
Here is an example of a chess game:
- State-based storing :

If we use state-based storing, we need to store snapshot of the board (the position of each piece) after each move.
- Event-based storing:

However when event-based approach is used, we need to store the initial position once at the beginning and it is enough to record moved piece only after each move.
Advantages of event sourcing:
- Evidentiary since update and delete are forbidden. If something goes wrong for whatever the reason, event store can be used to go back, replay events and figure out the problem.
- Events are recoverable. Any time events can be replayed to change or fix something in the system or the state of past can be obtained by replaying.
- Event data can be used to get insights to analyse user activity, preferences, etc.
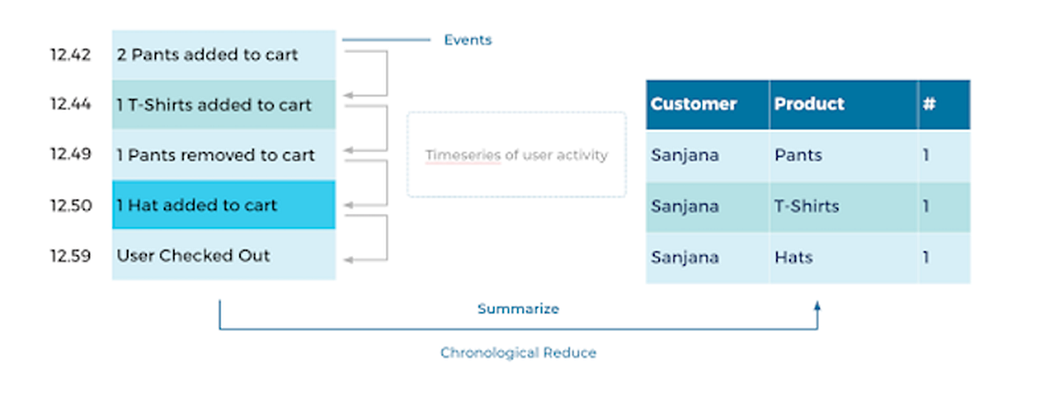
Chronological reduction is used to get the current state of the system. For example, when a user wants to see the shopping cart, events are reduced chronologically to get the current state of the shopping cart as seen below.
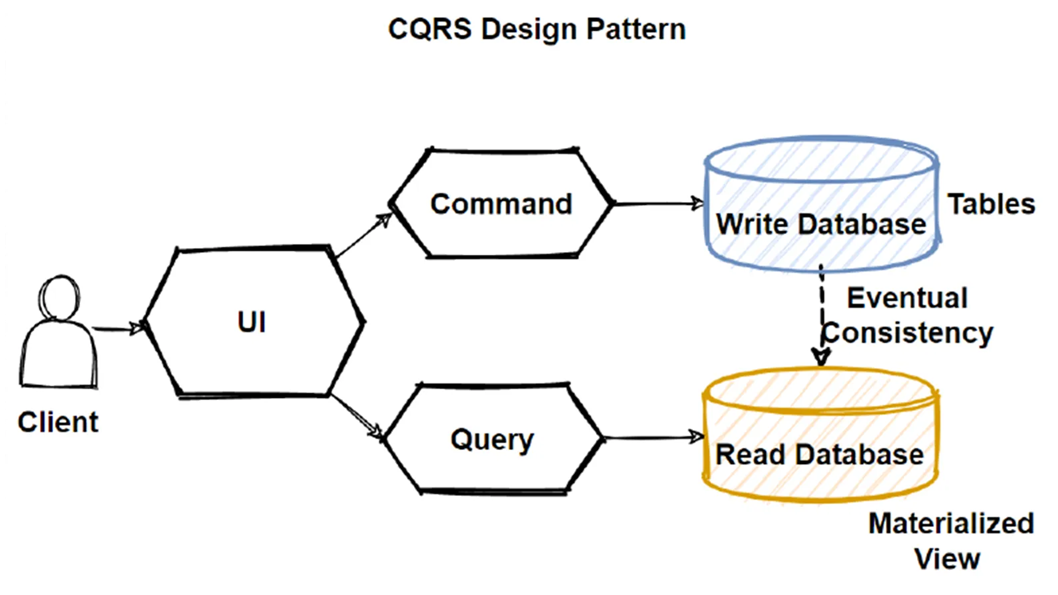
CQRS
Everything seems fine in event sourcing except one thing. What if i have millions of users and billions of events. Large chronological reductions will cause errors or very long response times.
At that point, Command Query Responsibility Segregation (CQRS) is coming into scene.
CQRS discriminates command and query databases from each other to improve performance, scalability, and security. Here commands are used to update data and queries are used to read data.
- Commands are events as we talked in sourcing. In write db, we store the commands.
- Commands may be processed asynchronously, using queues can be a good option.
- Queries never modifies database. They only reads db and returns DTOs.
As seen above, commands are stored into write database and queries read from read database. Read database is used to eliminate the large chronological reductions and increase query performance. Therefore, read databases should use their own data schemas which is optimised for queries. Materialized views can be used in read db to eliminate complex joins or ORM mappings.
Since separate read and write databases are used, they must be kept synchronised. This can be achieved by publishing an event when write database is updated.
Advantages:
- Independent scaling: read and write databases can be scaled independently.
- Optimized data schemas: Write and read sides can use schemas optimized for update or query.
- Security: Easier to ensure that write operations are performed by right fomain entities.
- Separation of concerns: More maintainable and flexible code. Since complex business logic goes into the write model, the read model can be relatively simple.
- Simpler queries. By storing a materialized view in the read database, the application can avoid complex joins when querying.
Disadvantages:
- Eventually consistent: Read database is eventually consistent since there is a synchronisation period. Therefore if consistency is important in an application, extra precautions will be needed.
- Separate database increase storage costs
- Separate database increase the need for know how on infrastructure and data access layer
- Data synchronisation between separate databases increases implementation and troubleshooting effort
- Command modals can be evolved over time and commands cannot be updated or deleted. Therefore versioning and handling all versions is needed where commands are processed.
Source: https://medium.com/@ocrnshn/event-sourcing-and-cqrs-9286e5578f93
Sick .NET Project: ASP.NET-Core-Clean-Architecture-CQRS-Event-Sourcing
Github link of the project: https://github.com/jeangatto/ASP.NET-Core-Clean-Architecture-CQRS-Event-Sourcing